📋 目录
1. 异步调用时序图
2. 高并发技术应用
3. 性能优化策略
---
异步调用时序图
1. 缓存查询接口流程(/api/v1/classify/check-cache)
场景:客户端先发送图片哈希,查询是否有缓存结果
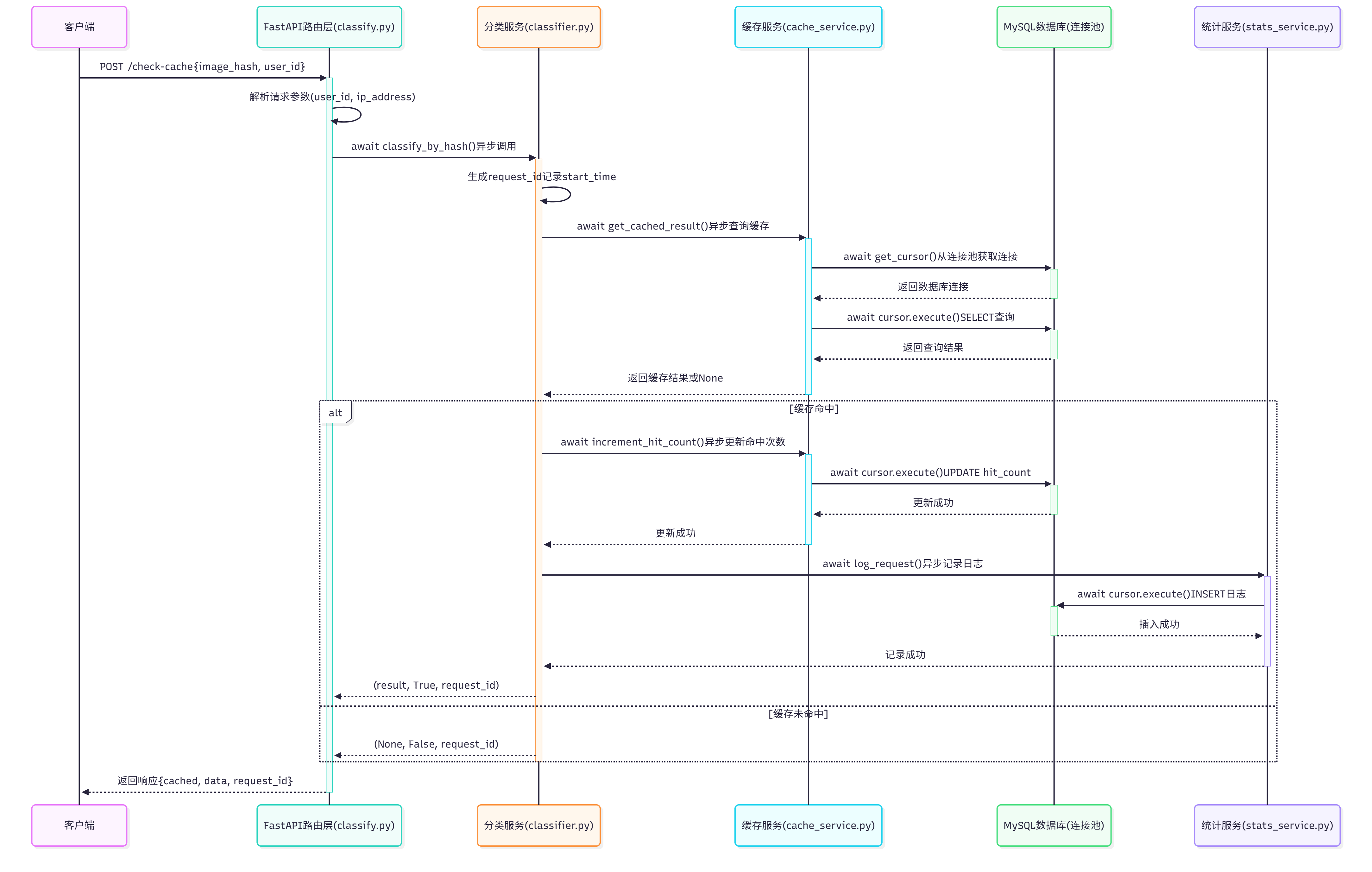
关键异步点:
- ✅ 所有数据库操作都是异步的(
await) - ✅ 使用连接池管理数据库连接,避免阻塞
- ✅ 统计日志记录是异步的,不阻塞主流程
---
2. 图片分类接口流程 - 缓存命中场景
场景:图片已存在于缓存中,直接返回结果
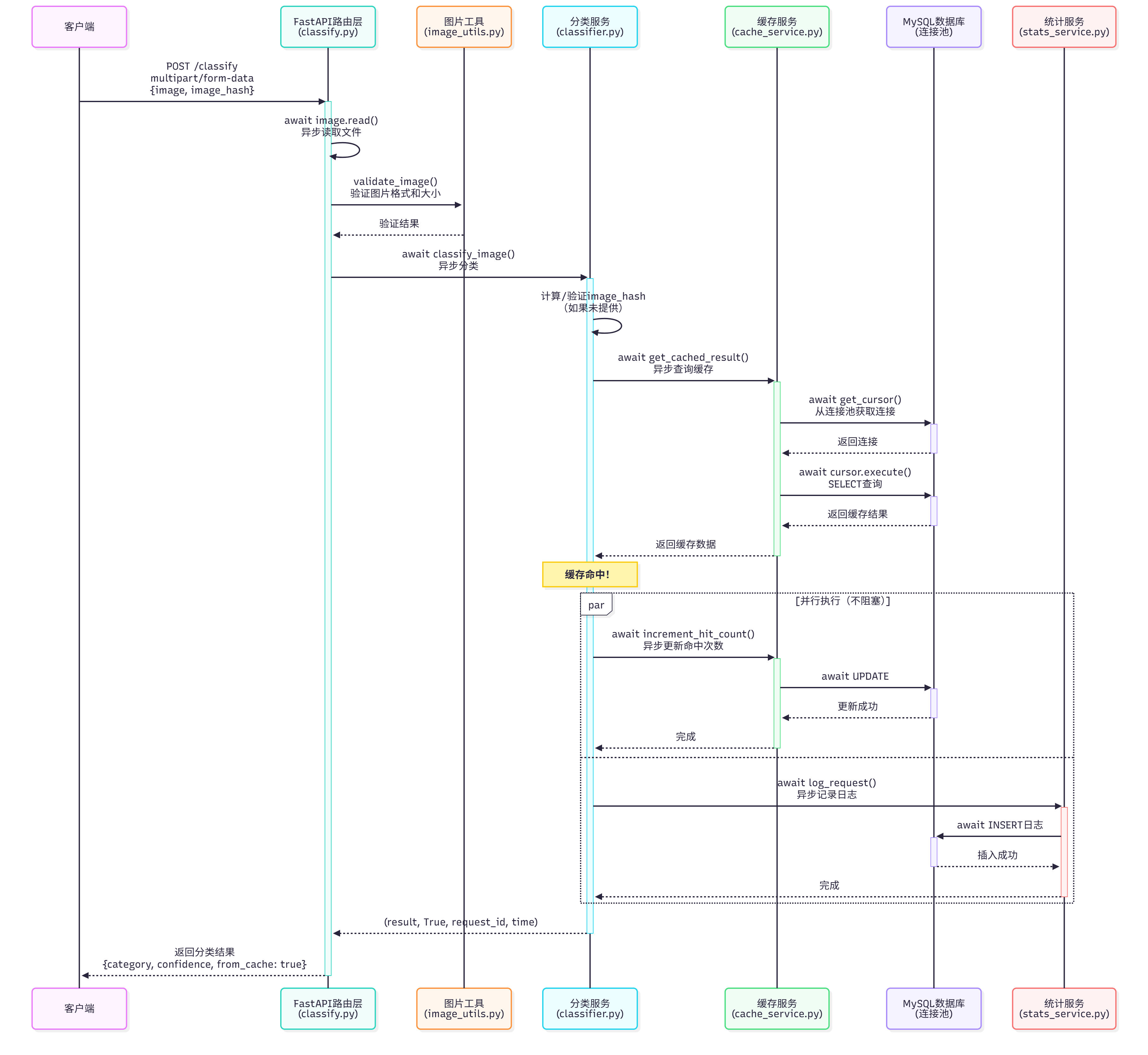
关键异步点:
- ✅ 文件读取是异步的(
await image.read()) - ✅ 缓存查询和统计日志可以并行执行(使用
par并行块) - ✅ 所有数据库操作都是异步的,不阻塞事件循环
---
3. 图片分类接口流程 - 缓存未命中 + 大模型调用
场景:缓存未命中,需要调用大模型API
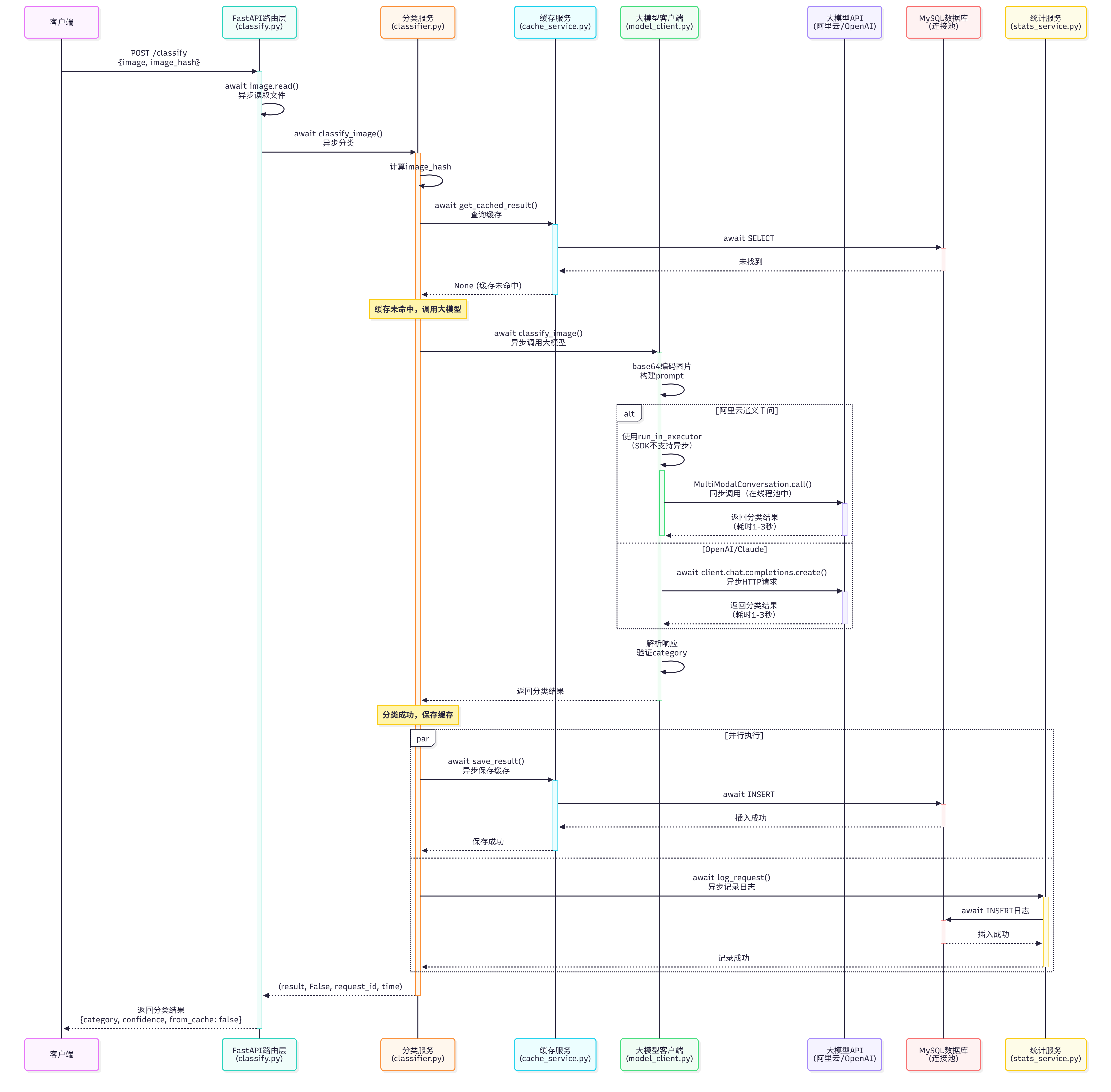
关键异步点:
- ✅ 大模型API调用是异步的(阿里云使用线程池,OpenAI/Claude使用异步HTTP)
- ✅ 保存缓存和记录日志并行执行,不相互阻塞
- ✅ 大模型调用期间,事件循环可以处理其他请求
---
4. 混合推理流程 - 大模型失败降级到本地推理
场景:大模型API调用失败,自动降级到本地ONNX模型
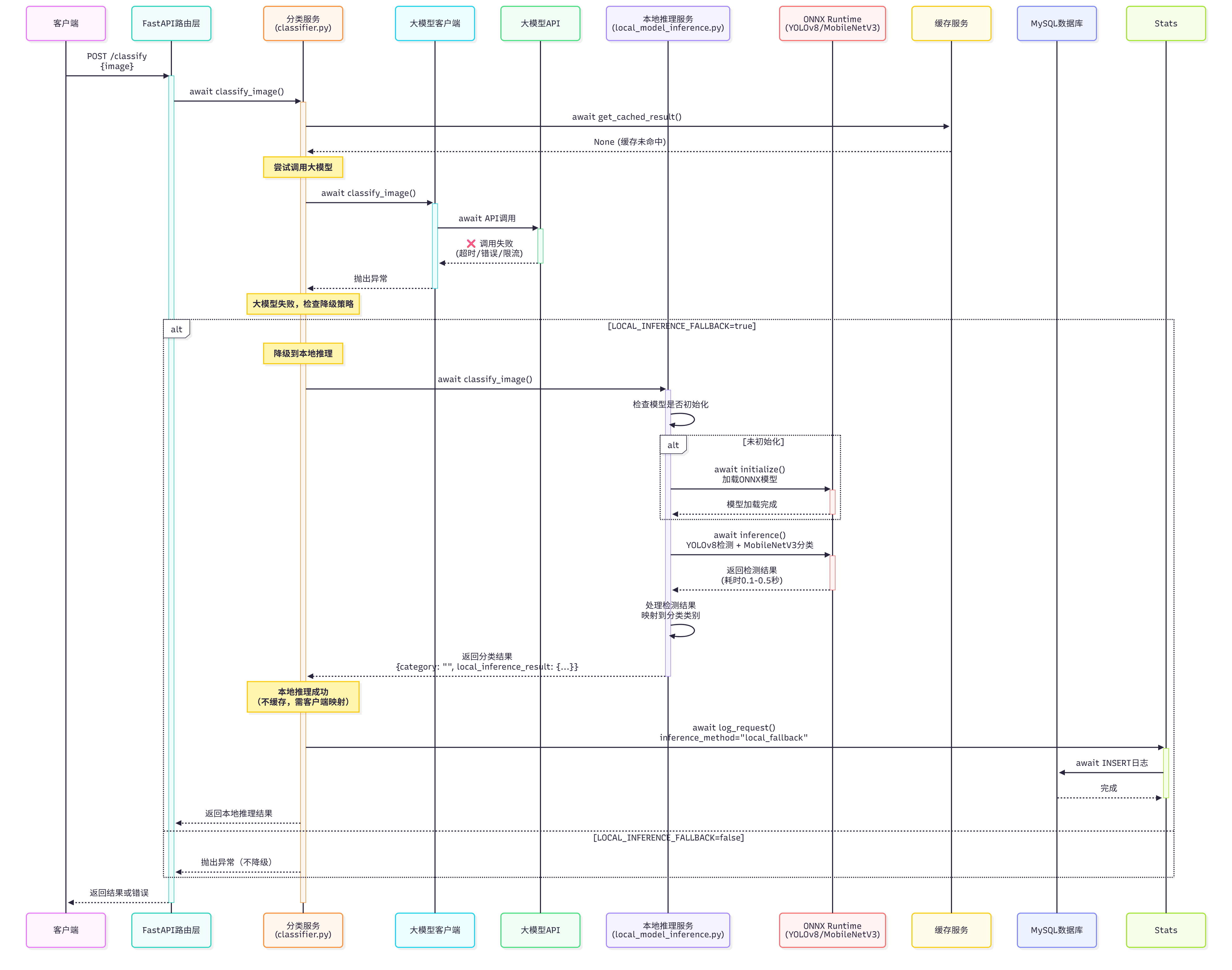
关键异步点:
- ✅ 本地推理也是异步的(
await),不阻塞事件循环 - ✅ 模型初始化只在第一次调用时执行
- ✅ 降级策略确保服务高可用
---
高并发技术应用
1. 异步I/O架构(AsyncIO)
#### 技术实现
核心原理:
- 使用Python的
asyncio库实现异步I/O - 所有阻塞操作都使用
await关键字,释放事件循环 - 事件循环可以同时处理数千个并发连接
代码示例:
高并发优势:
- ✅ 单线程处理多请求:一个事件循环可以处理数千个并发请求
- ✅ 非阻塞I/O:数据库查询、HTTP请求不会阻塞其他请求
- ✅ 资源高效:相比多线程,内存占用更少,上下文切换开销更小
---
2. 数据库连接池(Connection Pooling)
#### 技术实现
核心原理:
- 使用
aiomysql创建异步连接池 - 连接池维护一定数量的数据库连接,复用连接
- 避免频繁创建和销毁连接的开销
代码示例:
高并发优势:
- ✅ 连接复用:避免每次请求都创建新连接(耗时10-50ms)
- ✅ 连接限制:防止数据库连接数过多导致资源耗尽
- ✅ 自动管理:连接自动回收和重连,提高稳定性
配置建议:
---
3. 异步HTTP客户端(httpx)
#### 技术实现
核心原理:
- 使用
httpx进行异步HTTP请求 - 支持连接池和请求复用
- 不阻塞事件循环
代码示例:
高并发优势:
- ✅ 非阻塞请求:大模型API调用期间,可以处理其他请求
- ✅ 连接复用:HTTP连接可以复用,减少握手开销
- ✅ 超时控制:可以设置超时,避免长时间等待
---
4. 线程池执行器(ThreadPoolExecutor)
#### 技术实现
核心原理:
- 对于不支持异步的SDK(如阿里云dashscope),使用线程池执行
- 将同步调用包装在线程中,不阻塞事件循环
代码示例:
高并发优势:
- ✅ 兼容同步SDK:可以调用不支持异步的第三方库
- ✅ 不阻塞事件循环:同步调用在独立线程中执行
- ✅ 资源可控:线程池大小可以限制
---
5. 并行执行(并发优化)
#### 技术实现
核心原理:
- 使用
asyncio.gather()或asyncio.create_task()实现并行执行 - 多个独立的异步操作可以同时进行
代码示例:
高并发优势:
- ✅ 减少总耗时:两个操作并行执行,总时间 = max(操作1, 操作2)
- ✅ 提高吞吐量:相同时间内处理更多请求
- ✅ 资源利用:充分利用I/O等待时间
---
6. Gunicorn多进程架构
#### 技术实现
核心原理:
- 使用Gunicorn作为进程管理器
- 每个worker进程运行独立的FastAPI应用
- 充分利用多核CPU
配置示例:
高并发优势:
- ✅ 多核利用:每个CPU核心运行一个worker进程
- ✅ 进程隔离:一个进程崩溃不影响其他进程
- ✅ 负载均衡:Gunicorn自动分配请求到不同worker
性能计算:
---
7. 无状态设计
#### 技术实现
核心原理:
- 服务不保存会话状态
- 所有状态都存储在数据库中
- 支持水平扩展
代码示例:
高并发优势:
- ✅ 水平扩展:可以部署多个实例,负载均衡
- ✅ 无会话依赖:请求可以在任意实例处理
- ✅ 故障恢复:实例重启不影响服务
---
性能优化策略
1. 缓存优化
#### 策略
- 全局共享缓存:所有用户共享缓存结果
- 哈希去重:相同图片只调用一次大模型
- 缓存命中率:目标60-80%
#### 效果
---
2. 数据库优化
#### 策略
- 索引优化:
image_hash唯一索引,查询O(1) - 连接池:复用连接,减少连接开销
- 批量操作:支持批量查询缓存
#### 效果
---
3. 异步I/O优化
#### 策略
- 全异步架构:所有I/O操作都是异步的
- 并行执行:独立的操作并行执行
- 非阻塞等待:等待期间处理其他请求
#### 效果
---
4. 负载均衡优化
#### 策略
- 多进程部署:Gunicorn多worker
- 反向代理:Nginx负载均衡
- 健康检查:自动剔除故障实例
#### 效果
---
高并发性能指标
理论性能
| 指标 | 数值 | 说明 |
|---|---|---|
| 单worker并发 | 1000+ | 异步I/O支持高并发 |
| 4 workers总并发 | 4000+ | 多进程架构 |
| 缓存命中响应 | < 50ms | 数据库查询 + 网络延迟 |
| 大模型调用响应 | 1-3秒 | 取决于API响应时间 |
| 本地推理响应 | 100-500ms | ONNX模型推理 |
---
总结
高并发技术栈
1. 异步I/O:FastAPI + asyncio,单线程处理多请求
2. 连接池:aiomysql连接池,复用数据库连接
3. 多进程:Gunicorn多worker,充分利用多核CPU
4. 无状态设计:支持水平扩展
5. 智能缓存:减少大模型调用,提高响应速度
6. 并行执行:独立的异步操作并行执行
性能优势
- ✅ 高吞吐量:支持1000+ QPS
- ✅ 低延迟:缓存命中 < 50ms
- ✅ 高可用:混合推理策略,自动降级
- ✅ 成本优化:缓存机制节省70% API成本
- ✅ 资源高效:异步架构,内存占用小
---
文档版本: v1.0
最后更新: 2025-11-17
维护者: 芯图相册团队