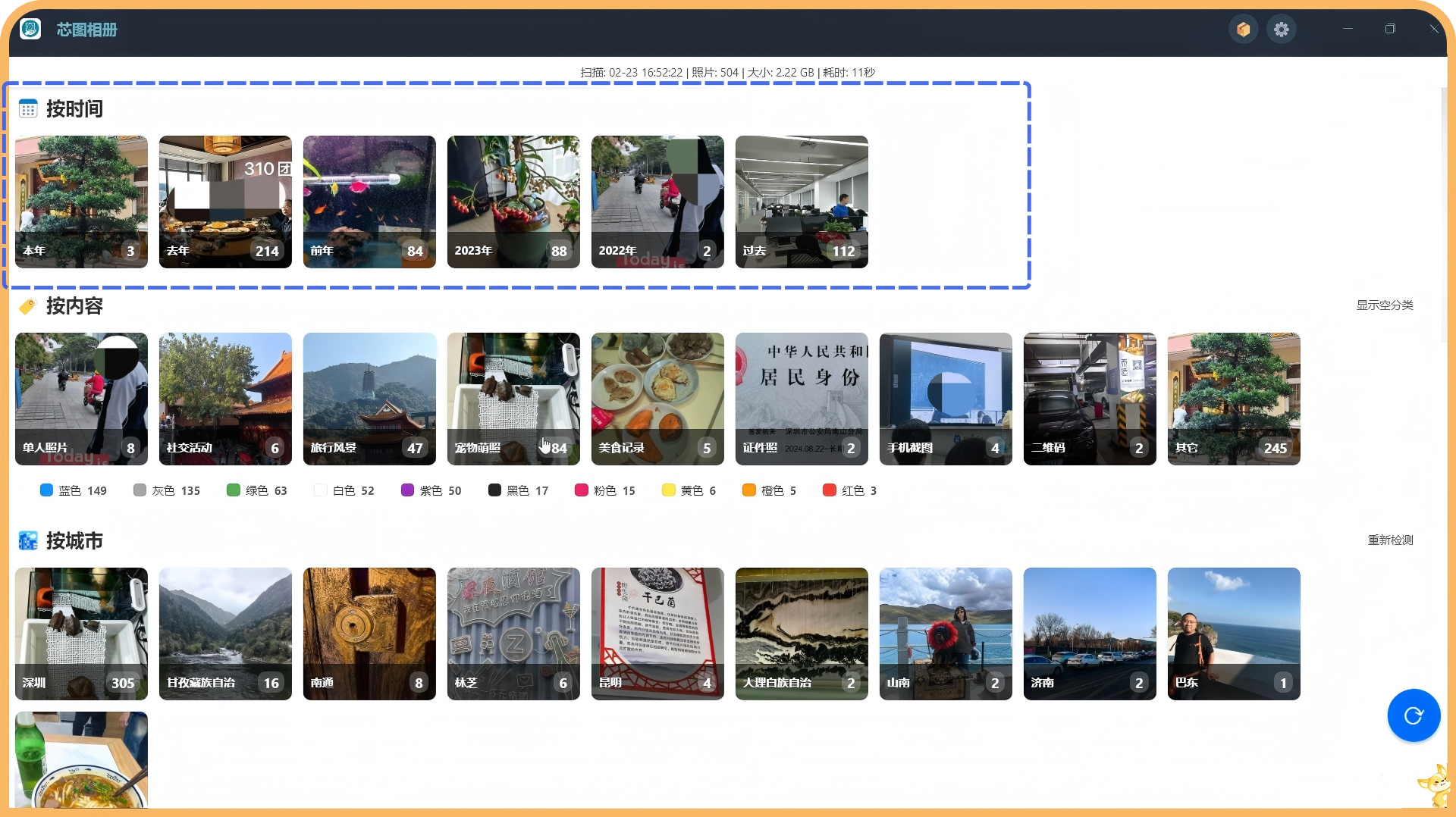
芯图相册在照片分类中提供「按城市」维度:根据照片的 GPS 坐标解析出拍摄城市,方便按地点浏览与整理。本文说明该能力背后的逆地址编码(Reverse Geocoding)实现逻辑,包括早期 V2 方案、遇到的问题,以及基于大模型的 V3 新方案,供关心照片分类技术实现的读者参考。
概述
芯图相册的按城市照片分类依赖逆地址编码接口:给定经纬度,返回国家、省/州、市/县等三级行政区信息。文档描述该接口从 V2 到 V3 的演进,包括当前 V2 的实现方式、成本与性能问题,以及基于大模型批量查询的 V3 方案(聚类 + LLM + 本地缓存),以及为何该方案更适合芯图相册的照片分类场景。
---
一、芯图相册当前实现方案(V2版本)
在芯图相册中,按城市照片分类需要为每张带 GPS 的照片解析出「最近城市」。V2 版本通过以下接口实现。
1.1 接口信息
- 接口路径:
POST /api/v2/location/nearest-cities - 功能: 批量查询多个坐标点的最近城市(最多500个),供照片分类按城市维度使用
- 返回: 每个坐标点的查询结果,包含城市信息、数据来源、查询耗时等
- 实现策略: 多级查询策略,优先使用本地数据库缓存,失败时调用外部API,最后降级到数据库模糊查询
1.2 核心查询流程
#### 流程图
二、当前方案对芯图相册照片分类的制约
2.1 成本问题
| 问题 | 说明 | 影响 |
|---|---|---|
| 高德API许可费用 | 需要每年5万的许可费用,不支持按量收费 | 固定成本高,不适合查询量小的场景 |
| 成本不可控 | 固定成本,无论使用量多少都需要支付 | 对于查询量不大的场景,成本效益低 |
2.2 功能限制
| 问题 | 说明 | 影响 |
|---|---|---|
| 不支持海外接口 | 高德API不支持海外地址查询 | 无法处理海外坐标,需要额外的Nominatim API |
| 不支持批量查询 | 每次只能查询一个地址,不支持并发批量查询 | 批量查询时性能差,需要多次API调用 |
| API限流严格 | 高德API:25/s,Nominatim API:1/s | 批量查询时响应时间长 |
2.3 性能问题
| 问题 | 说明 | 影响 |
|---|---|---|
| 批量查询性能差 | 100个坐标点需要100次API调用,耗时约30秒 | 用户体验差,响应时间长 |
| 串行处理 | 虽然使用并发,但受API限流限制,实际效果有限 | 无法充分利用并发优势 |
2.4 技术架构问题
| 问题 | 说明 | 影响 |
|---|---|---|
| 依赖多个外部API | 需要同时维护高德API和Nominatim API | 增加系统复杂度,维护成本高 |
| API稳定性依赖 | 外部API故障会影响服务可用性 | 需要完善的降级策略 |
---
三、芯图相册新方案(V3版本 - 基于大模型)
3.1 方案概述
为提升照片分类中「按城市」的体验并控制成本,芯图相册在 V3 中采用大模型批量查询方案:先用聚类算法将多张照片的坐标聚合成少量代表点(圆心),再批量调用大模型 API 查询这些圆心的城市信息,最后把结果映射回每张照片,从而大幅减少 API 调用次数与成本。
3.2 核心思路
关键决策点:
1. 聚类算法选择:
- DBSCAN算法:O(n log n)时间复杂度,自动确定聚类数量,适合照片地址分类场景
- 算法特性:
- 聚类范围可能超过
eps:如果桥梁点连接两个区域,聚类的范围可能超过eps(3km),这是DBSCAN算法的正常行为,可以接受 - 提高精度的方法:如果想更精确,应该通过缩小
eps来实现(如从3km缩小到2km),而不是拆分聚类
2. 参数设置:
- eps=3km:决定哪些点会被聚在一起(连续的点),这是影响聚类质量的关键因素
- 选择理由:3公里范围内通常是同一城市,准确性高
- 注意事项:聚类范围可能超过
eps(如桥梁点连接两个区域),这是算法正常行为,可以接受 - min_samples=1:对于照片地址分类应用更合适
- 原因:孤立点也需要查询,API调用次数相同,但代码更简单
- 优势:不需要处理噪声点的特殊情况,所有点都是聚类,逻辑更统一
- 说明:
min_samples的值不影响聚类质量(哪些点会被聚在一起由eps决定),只影响代码复杂度
3. 聚类中心点确定:
- 自适应方案:根据照片分布自动选择最合适的方法
- 景区场景(照片分布不均匀):使用最密集的点作为圆心
- 非景区场景(照片分布均匀):使用质心(坐标平均值)作为圆心
- 判断标准:通过密度方差判断是否存在明显的密集点
- 准确性说明:
- ✅ 大部分情况下准确:3公里范围内通常是同一城市,圆心坐标的位置信息可以代表圆内所有点
- ⚠️ 边界情况:3公里范围内可能有多个城市,圆心坐标的位置信息可能不够准确,但这是可以接受的权衡
4. 坐标匹配策略:
- 问题:大模型返回的query坐标可能与输入的圆心坐标不完全一致
- 解决方案:
- 在Prompt中明确要求返回query坐标(query_latitude, query_longitude)
- 使用query坐标进行精确匹配(无需模糊匹配)
- 如果精确匹配失败,使用模糊匹配作为降级策略(允许小误差)
- 优势:通过明确要求,大部分情况下可以精确匹配,代码逻辑更简单
5. 批量大小选择:
- 推荐:30个坐标/批次(平衡方案)
- 理由:
- 响应时间:20-25秒(可接受)
- Token消耗:~8000 tokens(在API限制内,32k)
- 准确性:良好,不易出错
- 适用场景:适合大多数场景,包括大规模场景(1000个坐标点约需3-4批处理)
- 对比:
| 批量大小 | 响应时间 | Token消耗 | 准确性 | 适用场景 |
|---|---|---|---|---|
| 10个 | ~8-12秒 | ~3000 tokens | ⭐⭐⭐⭐⭐ | 质量优先 |
| 30个 | ~20-25秒 | ~8000 tokens | ⭐⭐⭐⭐ | 推荐(平衡) |
| 50个 | ~30-40秒 | ~13000 tokens | ⭐⭐⭐⭐ | 性能优先 |
- 关键原则:
- ✅ 准确性优先:小批次更准确
- ✅ 响应时间:控制在30秒以内
- ✅ Token消耗:不超过API限制(32k)
- ✅ 错误恢复:便于重试和降级
---
四、架构决策:为什么芯图相册选择大模型做照片分类按地址
4.1 实际业务场景
芯图相册的照片分类需要「按地址/按城市」能力,本质是一个照片按地址分类系统,核心需求是:
1. 支持全球地址的三级分类:
- 国家(Country)
- 一级行政区(省/州,Admin1)
- 二级行政区(市/县,Admin2)
- 不需要精确到街道级别
2. 应用起始阶段的成本约束:
- 无法承担高价的年度许可费用(如高德API的¥50,000/年)
- 需要按量付费的灵活模式
- 成本需要随业务增长而线性增长,而非固定成本
3. 数据稳定性要求:
- 一个坐标的三级行政区信息一般不会变化
- 除非发生地区独立、行政区划重大调整等罕见事件
- 这意味着一次查询,长期有效,本地缓存价值高
4. 准确度要求适中:
- 不需要精确到街道级别
- 三级行政区信息即可满足照片分类需求
- 90-95%的准确度即可接受
4.2 传统三方接口的局限性
#### 高德地图API的限制
1. 固定年度费用:
- ¥50,000/年,无论使用量多少
- 对于应用起始阶段,这是一笔巨大的固定成本
- 即使查询量很小,也必须支付全额费用
2. 功能限制:
- 不支持海外地址:只能处理中国境内的坐标
- 不支持并发批量查询:每次只能查询一个坐标
- 对于需要处理全球照片的应用,这些限制是致命的
3. 成本结构不合理:
- 查询量小:固定费用不划算
- 查询量大:固定费用虽然可以接受,但功能受限
#### Nominatim API的限制
1. 功能限制:
- 不支持并发批量查询:每次只能查询一个坐标
- 对于需要处理大量照片的应用,串行查询效率极低
2. 准确度问题:
- 实际测试显示,高德API的准确度不如大模型
- 经常出现字段缺失的情况
- 对于三级行政区信息的提取,大模型表现更好
3. 成本问题:
- 虽然免费,但功能受限
- 无法满足批量查询的需求
4.3 大模型方案的优势
#### 1. 成本优势:按量付费,灵活可控
成本对比:
| 查询量 | 高德API(固定费用) | LLM方案(按量付费) | 成本节省 |
|---|---|---|---|
| 1,000次/年 | ¥50,000 | ¥10-20 | 99.98% |
| 10,000次/年 | ¥50,000 | ¥100-200 | 99.6% |
| 100,000次/年 | ¥50,000 | ¥1,000-2,000 | 96-98% |
| 500,000次/年 | ¥50,000 | ¥5,000-10,000 | 80-90% |
关键优势:
- ✅ 起始成本低:应用初期只需支付实际使用的费用
- ✅ 成本随业务增长:查询量增加时,成本线性增长
- ✅ 无固定成本压力:不会因为固定费用而影响业务决策
#### 2. 功能优势:全球覆盖,批量处理
功能对比:
| 功能 | 高德API | Nominatim | LLM方案 |
|---|---|---|---|
| 支持海外地址 | ❌ | ✅ | ✅ |
| 批量查询 | ❌ | ❌ | ✅ |
| 并发处理 | ❌ | ❌ | ✅ |
| 三级行政区信息 | ✅ | ⚠️(准确度低) | ✅ |
| 中英文支持 | ✅ | ⚠️(英文为主) | ✅ |
关键优势:
- ✅ 全球覆盖:支持全球任意坐标的三级行政区查询
- ✅ 批量处理:一次API调用可处理30个坐标(通过聚类优化)
- ✅ 并发支持:可以同时处理多个批量查询请求
#### 3. 准确度优势:实际测试表现更好
实际测试结果:
根据我们的测试,大模型在三级行政区信息提取方面的准确度优于高德API:
- 高德API的问题:
- 经常出现字段缺失(如缺少
admin1_name_en或admin2_name_en) - 对于某些地区的行政区划信息不够完整
- 海外地址完全无法处理
- LLM方案的优势:
- 能够基于地理知识库提供完整的三级行政区信息
- 支持全球任意地区,包括小国、特殊地区
- 中英文信息完整,适合国际化应用
#### 4. 数据稳定性:一次查询,长期有效
关键特性:
- ✅ 三级行政区信息稳定:一个坐标的三级行政区信息一般不会变化
- ✅ 本地缓存价值高:查询结果可以长期缓存,减少重复查询
- ✅ 成本进一步降低:通过本地数据库缓存,实际API调用量大幅减少
缓存策略:
- 本地数据库缓存命中率通常 > 70%
- 对于已缓存的坐标,响应时间 < 1秒,成本为0
- 只有未命中的坐标才需要调用LLM API
4.4 性能评估
#### 示例1:中等规模(100个坐标点,本地数据库命中率70%)
| 步骤 | V2方案 | V3方案 | 说明 |
|---|---|---|---|
| 本地查询 | 70个命中,< 1秒 | 70个命中,< 1秒 | 相同 |
| 聚类算法 | - | 30个坐标,< 1秒 | V3新增 |
| 外部API调用 | 30次 × 1秒 = 30秒 | 1批(30个)× 20秒 = 20秒 | V3批量查询更快 |
| 结果映射 | - | < 100ms | V3新增 |
| 总耗时 | ~30秒 | ~21秒 | V3更快 |
#### 示例2:大规模(1000个坐标点,本地数据库命中率70%)
| 步骤 | V2方案 | V3方案 | 说明 |
|---|---|---|---|
| 本地查询 | 700个命中,< 1秒 | 700个命中,< 1秒 | 相同 |
| 聚类算法 | - | 300个坐标,< 2秒 | V3新增 |
| 外部API调用 | 300次 × 1秒 = 300秒(5分钟) | 10批(30个/批)× 20秒 = 200秒 | V3批量查询更快 |
| 结果映射 | - | < 500ms | V3新增 |
| 总耗时 | ~300秒(5分钟) | ~202秒(3.4分钟) | V3更快 |
| Token消耗 | - | ~80,000 tokens(10批×8000) | 分批处理,每次在限制内 |
关键优势:
- ✅ V3方案在大规模场景下优势更明显:1000个坐标点,V3方案节省约1.6分钟
- ✅ Token消耗完全可控:通过分批处理(30个/批),每次调用token数在合理范围内(~8000 tokens),总计约80k tokens,但分10次调用,每次都在限制内
- ✅ 响应时间可接受:即使1000个坐标点,总耗时约3.4分钟,比V2方案的5分钟快约33%
4.5 成本评估
#### 示例1:中等规模(日查询1,000次,年查询365,000次,本地数据库命中率70%)
| 方案 | 年成本 | 说明 |
|---|---|---|
| V2方案(高德API) | ¥50,000 | 固定成本,无论使用量 |
| V3方案(大模型) | ¥1,643-3,285 | 109,500次 × ¥0.01-0.02(30%需要API) |
| 节省 | ¥46,715-48,357 | 约93-97% |
#### 示例2:大规模(单个用户1000个坐标点)
场景:单个用户去1000个地方,本地数据库命中率70%
| 方案 | API调用次数 | Token消耗 | 成本估算 |
|---|---|---|---|
| V2方案(高德API) | 300次(30%需要API) | - | 固定成本已包含 |
| V3方案(大模型) | 10批(30个/批) | ~80,000 tokens(分10次调用) | ¥0.20-0.40(按¥0.01-0.02/次) |
关键结论:
- ✅ 单个用户1000个地方,V3方案成本仅需¥0.20-0.40
- ✅ Token消耗完全可控:通过分批处理,每次调用~8000 tokens,远低于API限制(32k),总计约80k tokens但分10次调用
- ✅ 成本优势明显:即使大规模场景,V3方案成本仍然很低
- ✅ 1000个地方是合理的上限:通过聚类和分批处理,token消耗、响应时间和成本都在合理范围内
4.6 方案创新点
#### 创新1:应用transformer进行地址逆编码
核心思想:
- 将未命中本地数据库的坐标进行DBSCAN聚类
- 每个聚类选择一个中心点(3km半径内)
- 将多个聚类的中心点批量发送给LLM(最多30个/批)
- LLM返回每个中心点的三级行政区信息
- 将结果映射回原始坐标
创新价值:
- ✅ 大幅减少API调用次数:100个坐标可能只需要3-5次API调用
- ✅ 成本降低:相比单个查询,批量查询的成本降低90%以上
- ✅ 效率提升:批量查询的响应时间远小于100次单个查询的总时间
#### 创新2:自适应聚类中心选择
核心思想:
- 对于景区等密集区域:选择密度最高的点作为中心(代表核心位置)
- 对于均匀分布区域:选择聚类中心(平均值)作为中心(代表整体位置)
创新价值:
- ✅ 更准确的代表点:景区照片通常集中在核心位置,选择密度最高的点更准确
- ✅ 更好的用户体验:用户看到的城市位置更接近实际拍摄的核心区域
#### 创新3:本地数据库 + LLM混合架构
核心思想:
- 第一层:本地数据库查询(3km内),命中率 > 70%
- 第二层:LLM批量查询(未命中的坐标),通过聚类优化
- 第三层:数据库保存(所有查询结果),提高未来命中率
创新价值:
- ✅ 成本最优:本地数据库命中率高,实际API调用量少
- ✅ 性能最优:本地查询 < 1秒,LLM批量查询 20-25秒/批
- ✅ 可扩展性强:随着数据积累,本地数据库命中率持续提升
4.7 为什么这个方案适合芯图相册的照片分类场景
#### 1. 成本敏感的应用起始阶段
场景:
- 应用刚起步,用户量小,查询量有限
- 无法承担¥50,000/年的固定费用
- 需要按量付费的灵活模式
LLM方案的优势:
- ✅ 起始成本低:查询量小,成本低
- ✅ 成本可控:随业务增长,成本线性增长
- ✅ 无固定成本压力:不会因为固定费用而影响业务决策
#### 2. 全球照片分类需求
场景:
- 芯图相册用户可能在全球任意地点拍摄照片,照片分类需支持按城市维度
- 需要支持全球地址的三级分类
- 高德API无法满足海外地址需求
LLM方案的优势:
- ✅ 全球覆盖:支持全球任意坐标
- ✅ 统一接口:不需要区分国内外,统一处理逻辑
- ✅ 中英文支持:完整的中英文三级行政区信息
#### 3. 批量处理需求
场景:
- 芯图相册用户一次可能扫描或导入数百张照片,照片分类需批量解析城市
- 需要批量查询坐标对应的城市信息
- 传统API不支持批量查询,串行查询效率极低
LLM方案的优势:
- ✅ 批量查询:一次API调用可处理30个坐标
- ✅ 聚类优化:通过DBSCAN聚类,进一步减少API调用次数
- ✅ 效率提升:批量查询的响应时间远小于串行查询
#### 4. 数据稳定性要求
场景:
- 一个坐标的三级行政区信息一般不会变化
- 不需要精确到街道级别
- 查询结果可以长期缓存
LLM方案的优势:
- ✅ 数据稳定:三级行政区信息变化极少
- ✅ 缓存价值高:一次查询,长期有效
- ✅ 成本降低:通过本地数据库缓存,实际API调用量大幅减少
附录:DBSCAN 算法详解(用于照片分类中的坐标聚类)
A.1 算法概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 是一种基于密度的聚类算法,特别适合处理空间数据(如坐标点)。
为什么 DBSCAN 特别适合芯图相册的照片地址分类场景?
在芯图相册的照片分类场景中,用户往往在同一景区或地点拍摄多张照片,这些照片的 GPS 坐标会聚集在一起(通常在几百米到几公里内)。DBSCAN 的基于密度的特性与这种地理分布高度契合:
1. 自然聚类:
- 同一景区的照片坐标会自然形成密集的聚类
- DBSCAN可以自动识别这些密集区域,将它们聚合成一个圆心
- 例如:在故宫拍摄的10张照片,坐标都在1公里范围内,会被聚合成1个圆心
2. 减少API调用:
- 10张照片 → 1个圆心 → 1次大模型API调用
- 相比逐个查询,API调用次数减少90%
3. 处理孤立照片:
- 如果某张照片的坐标远离其他照片(噪声点),DBSCAN会自动识别
- 可以单独处理,不影响其他照片的聚类
实际场景示例:
A.2 算法原理
#### A.2.1 核心概念
1. 核心点(Core Point):在半径 eps 内至少有 min_samples 个点的点
2. 边界点(Border Point):在核心点的邻域内,但自身不是核心点
3. 噪声点(Noise Point):既不是核心点也不是边界点的点
#### A.2.2 算法流程
#### A.2.3 密度可达性(Density Reachability)
什么是密度可达?
密度可达是DBSCAN算法的核心概念,用于判断两个点是否属于同一个聚类。
定义:
- 直接密度可达(Directly Density-Reachable):
- 点B在点A的
eps邻域内 - 点A是核心点
- 那么点B从点A直接密度可达
- 密度可达(Density-Reachable):
- 如果存在一系列点:A → P1 → P2 → ... → Pn → B
- 其中每个点都从前一个点直接密度可达
- 那么点B从点A密度可达
- 密度连接(Density-Connected):
- 如果存在一个核心点C,使得点A和点B都从C密度可达
- 那么点A和点B密度连接
示例:
关键特性(简化理解):
- 核心思想:连续的点(距离不超过
eps的点)归类为一个聚类 - 通俗理解:如果点A和点B距离
- 核心点的作用:核心点可以"连接"其他点,如果两个核心点之间可以通过一系列不超过eps的距离连接,它们属于同一个聚类
- 关键特性:聚类结果不受起始点选择的影响(这是DBSCAN算法的确定性保证)
- 无论从哪个点开始,只要点之间通过不超过eps的距离连接(密度可达),它们都会被归入同一个聚类
- 起始点的选择只影响算法的执行顺序,不影响最终的聚类结果
A.3 参数说明
1. eps 参数:决定"连续的点"的定义(距离阈值),这是影响聚类质量的关键因素
- 如果两个点距离
- 如果两个点距离>eps,它们不会被聚在一起
- 聚类质量主要由
eps决定
2. min_samples 参数:只影响哪些点被标记为噪声点,或哪些点会形成独立聚类
- 不影响哪些点会被聚在一起(这是由
eps决定的) - 只影响孤立点的处理方式(噪声点 vs 独立聚类)
参数设置:
- eps(半径):邻域半径,对于坐标聚类,通常设置为3公里(转换为度:3/111 ≈ 0.027度)
- min_samples(最小样本数):形成核心点所需的最小点数
A.4 关于 min_samples=1 的讨论
如果 min_samples=1,意味着:
- 每个点都可以成为核心点(因为每个点至少包含自己,所以至少有1个点)
- 不会产生噪声点:所有点都会被分配到某个聚类(即使是单点聚类)
- 失去边界点的概念:所有点都是核心点(没有边界点,也没有噪声点)
- 聚类可能过于分散:如果两个点之间的距离刚好超过
eps,它们会形成两个独立的聚类 - API调用次数相同:
min_samples=1时,孤立点形成单点聚类;min_samples>=2时,孤立点被标记为噪声点 - 但都需要调用API:无论是单点聚类还是噪声点,都需要调用API进行逆地址编码,所以API调用次数相同
关键理解:
min_samples不影响哪些点会被聚在一起(这是由eps决定的)- 密集区域的定义取决于聚类包含的点的数量,而不是
min_samples的值 - 如果多个点距离
min_samples 是多少) min_samples只影响哪些点会被标记为核心点,不影响聚类结果
示例对比:
推荐设置:
对于照片地址分类应用场景:
- min_samples=1(推荐):更适合这个应用场景
- 优势1:处理更简单,所有点都形成聚类,不需要处理噪声点(label=-1)的特殊情况
- 优势2:代码逻辑更统一,所有点都是聚类,不需要区分噪声点和聚类
- 优势3:API调用次数相同(无论是单点聚类还是噪声点,都需要调用API)
- 优势4:不会遗漏任何点,所有照片都会被处理
- 说明:对于这个应用,孤立点也需要查询,所以
min_samples的值不影响聚类质量,只影响代码复杂度
- min_samples=2(备选):如果需要区分密集区域和孤立点
- 优势:可以区分密集区域(聚类)和孤立点(噪声点)
- 劣势:需要处理噪声点的特殊情况,代码更复杂
- 适用场景:如果需要对密集区域和孤立点做不同处理
A.5 实现示例
A.6 算法特点
| 维度 | DBSCAN算法 |
|---|---|
| 时间复杂度 | O(n log n)(使用索引) |
| 聚类质量 | ⭐⭐⭐⭐⭐(基于密度) |
| 噪声处理 | ✅ 自动识别噪声点 |
| 聚类数量 | ✅ 自动确定 |
| 实现复杂度 | ⭐⭐⭐(需要scikit-learn) |
| 依赖项 | scikit-learn |
| 适用场景 | 大规模数据(>1000点) |
DBSCAN的优势(即使 min_samples=1 仍然有效):
1. 自动确定聚类数量:不需要预先指定聚类数量,算法会自动发现
2. 处理噪声点:孤立点会被自动识别为噪声点(label=-1),可以单独处理
- ⚠️ 重要说明:如果
min_samples=1,每个点都可以成为核心点(因为至少包含自己) - 关键:当
min_samples=1时,不会产生噪声点,所有点都会被分配到某个聚类(即使是单点聚类) - 结论:只有当
min_samples>=2时,孤立点才会被标记为噪声点
3. 基于密度:更符合地理分布的特点(城市通常聚集在一起)
- 即使
min_samples=1,如果两个点在eps范围内,仍然会被聚在一起
4. 性能更好:使用索引结构(ball_tree),时间复杂度为 O(n log n)
DBSCAN的劣势:
1. 需要安装scikit-learn:增加了依赖项
2. 参数调优:需要调整 eps 和 min_samples 参数
3. 实现复杂度:需要安装scikit-learn依赖
4. 起始点选择的影响:虽然DBSCAN通过"密度可达"概念保证结果一致性,但在某些边界情况下,起始点的选择可能会影响聚类结果
A.7 边界情况讨论
在某些边界情况下(如两个密集区域之间有一个"桥梁"点),min_samples 的值会影响桥梁点是否能连接两个区域:
示例场景:
A.8 推荐使用场景
推荐使用场景:
- ✅ 坐标点数量较多(>100个)
- ✅ 需要处理噪声点(孤立点)
- ✅ 对聚类质量要求较高
- ✅ 可以接受额外的依赖项(scikit-learn)
不推荐使用场景:
- ❌ 坐标点数量很少(<50个)
- ❌ 不想增加依赖项(scikit-learn)
---
结语
芯图相册的照片分类提供按时间、按内容、按城市等多维度整理能力。其中「按城市」依赖逆地址编码:从照片 EXIF 中的 GPS 坐标解析出国家、省/州、市/县。本文介绍了从 V2(高德/Nominatim)到 V3(大模型 + DBSCAN 聚类 + 本地缓存)的演进,以及为何在成本、全球覆盖和批量处理上,大模型方案更适配芯图相册的照片分类场景。若你正在做智能相册或照片分类产品,可参考上述架构与参数设计。